
In the Fight Against Fraud, Not all Graphs Are Created Equal
How to build a streamlined approach to large-scale knowledge graph frameworks, focusing on clarity and effectiveness.


Graphs are crucial to the ecosystems of big data and AI-enabled fraud detection. From well-hyped graph databases and providers of enterprise knowledge graphs to analytical engines and the SME consultants who apply them, the territory is vast. Can large-scale knowledge graph frameworks be more streamlined? Can applied intelligence fuel a fraud-decisioning platform without requiring unnecessary infrastructure? In this article, we explore how these goals can be achieved.
Fraud investigators need agility and graphs-at-scale
Fraud investigators need to resolve issues related to messy, duplicated, or incomplete financial data, usefully unify data across silos, eliminate duplication, and expose synthetic identities through powerful entity resolution. Implementing graphs effectively extends far beyond using a graph database for storage and the querying of relatively fixed data governed by a strict typology. Instead, it entails fully utilizing graph intelligence, enabling dynamic large-scale knowledge graphs to find hidden patterns alongside localized ego graphs—a.k.a. networks—for deep investigation. Graphs can link people, businesses, accounts, devices, and transactions, and leverage contextual understanding and advanced algorithms to detect complex fraud patterns, such as mule networks, collusion, and synthetic ID clusters. Crucially, the graphs deliver enriched, prioritized cases directly to investigators, reducing time they spend on false positives and enabling effective action.
Analyst organizations have highlighted how knowledge graphs can help navigate billions of relationships to contextualize AI, including in fraud detection. However, for AI-based fraud detection workflows, investigators need context beyond queried connections in a relatively static graph database. Data is messy, and constantly changing. Target requirements aligning with new fraud scenarios require useful alerts for focused investigations. With storage cheap and processing power increasingly accessible, large-scale knowledge graphs are more readily available to investigators outside of database technologies.
How knowledge graphs generate intelligence for fraud use cases
Drawing from many external data sources, knowledge graphs organize entities (such as users, accounts, devices, and transactions) into structured, organized networks of relationships that reflect real-world interactions. The enriched representation, centered on domain knowledge (e.g., known fraud typologies or risk scores), allows systems to detect suspicious patterns that span multiple entities. These patterns can be repeated transaction paths, unusual connections between accounts, or even shared IP addresses. This is why knowledge graphs are well positioned to identify and address fraud.
However, fraud comes in many shapes and sizes. Some are anomalistic lone wolves—the proverbial needle in the haystack. Others are criminal communities hidden in plain sight. As a result, graph data science and analytics strategies are needed to accompany knowledge graph structures; they can identify relational signals that traditional tabular approaches often miss.
Here are three common approaches:
The Page Rank algorithm seeks central entities and highlights them. The technique can help whitelist high-trust accounts and highlight low-trust accounts—a signal booster in a fraud scorecard.
This is particularly helpful when looking across consortium, multi-bank, and regulator data sets.
Graph neural networks (GNNs) can learn patterns from the context of interactions among graphed entity types (e.g., customer, merchant, device) to accurately model and infer anomalous or suspicious behaviors. They are impactful in complex fraud scenarios that have multiple layers of deception.
For example, a knowledge graph might link a transaction to a merchant category, geographic location, or historical risk score. Then GNNs can use that link to better model and detect interactions.
Multi-hop analysis techniques consider a knowledge graph in its large-scale entirety, working from a list of "seed" entities to return a configurable, ranked set of entities for investigation.
Multi-hop analysis is the most complex of these three techniques. So before we move on, let's take a closer look at how it works and the insights it can provide.
A multi-hop example
By using global corporate registry data and resolving entities within it, it can result in a network—one that can be converted into a knowledge graph with millions of connected entities. Next, we can take 13 "seed" businesses suspected of money laundering. These are identified in the publicly available International Consortium of Investigative Journalists’ (ICIJ) Cyprus Confidential investigations, which explores Cypriot businesses implicated in evading sanctions. By examining these in connection with the network, multi-hop analysis seeks to identify entities with a sufficiently high "contextual centrality"—that is, a proximity through the network connections to the 13 seed businesses, or other suspect entities connected to them.
Through such research, a further 65 newly identified entities worthy of investigation can be identified, beyond those previously mentioned in ICIJ’s reports. 19 of these entities are individuals, around half of whom feature on existing watchlists, as either Special Interest or Politically Exposed Persons.
More data silos, or greater intelligence?
Databases, including graph databases, are data storage and retrieval vehicles, and excel at answering queries like “find all nodes connected to this customer.” However, users still need to model fraud typologies and apply queries—and they often must do it in an unfamiliar programming language. That can be a problem. Fraud investigations don’t need another data silo with static datasets and more overheads.
Fraud investigations, however, do need graphs predicated on accurate unified data, with full entity resolution to eliminate duplication and silos. They also must be able to pinpoint and expose synthetic identities, which can get created at any time. Focused knowledge graphs should dynamically link real people, businesses, accounts, devices, and transactions as datasets change. Investigators, too, need to match the speed and agility of bad actors by deploying context, skill, and relevant algorithms as part of an adaptable infrastructure—for example, to automatically identify changing patterns of mule networks, collusion, or synthetic ID clusters.
Consider our multi-hop case. Graph databases struggle to navigate beyond 3 or 4 hops without hitting computing limits. Key actors are often present in the network, but need not be directly connected to known entities. Knowledge graphs should navigate many hops with ease to directly alert investigators of enriched, prioritized cases.
Why use entity-resolved knowledge graphs?
Consider COVID-era government loan fraud. Fraud rings exploited weak data verification by applying with multiple identities, each one slightly altered. By using expert querying, graph databases could show those connections, but only if those identities had been resolved ahead of time to reveal they were the same person or business. Without entity resolution, risk signals would remain invisible in the database. Similarly, in account takeover fraud, a customer’s device, IP address, or phone number may connect to multiple accounts. Unless the underlying data is resolved and linked consistently, potential red flags will appear as noise rather than evidence. Unifying validated contextualized entities allows the knowledge graph to clearly reveal a bigger picture.
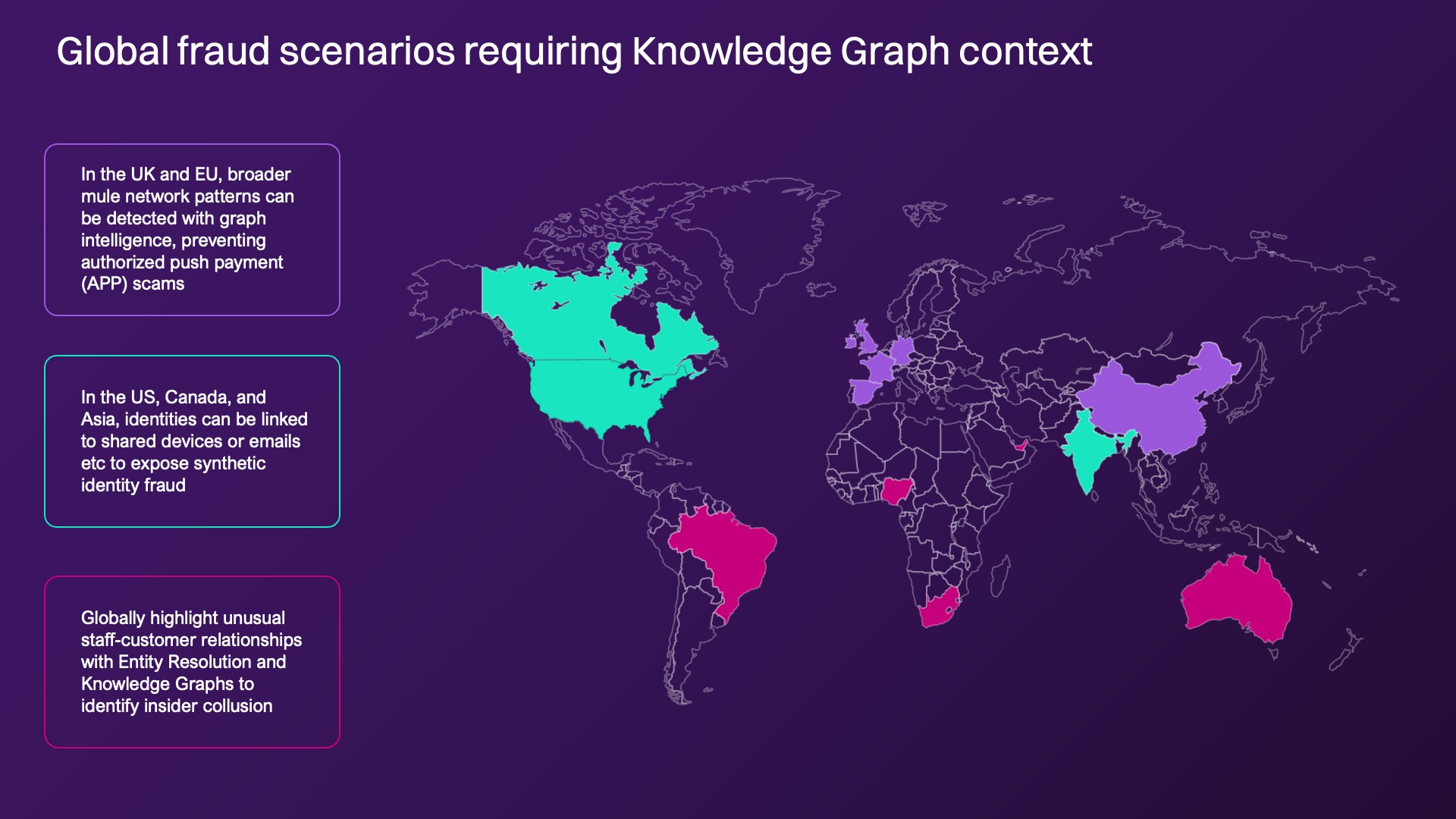
Global contextual scenarios
In the UK fraudsters using authorized push-payment scams convince victims to move money into mule accounts. A database query can highlight account-to-account transfers, but without entity resolution and contextual enrichment, the broader mule network remains hidden. Graph intelligence detects not just the transfer, but also patterns of fraudulent network behavior across accounts, devices, and beneficiaries.
In the US and Asia, criminals combine real and fake data to build “new” customers; this is called synthetic identity fraud. Graph databases may see transactions linked to these identities, but without resolving duplicates and overlaps, they miss the dozens of identities that share the same email or device. Fraud solutions should expose this anomaly automatically.
In cases of insider collusion in global banks, in which staff colludes with external actors, graph queries may flag transactions but miss the trusted insider. Entity resolution with knowledge graphs can better highlight unusual staff-customer relationships that do not surface with simple queries.
Infrastructure or intelligence?
Proof lies in outcomes. Institutions that adopt contextual graph-based solutions report:
Up to 80% reduction in investigation time
Significant decreases in false positives, improving customer experience
Exposure of large-scale fraud rings that rule-based or query-driven graph systems missed entirely
Because payments and transactions—from credit cards to wires to peer-to-peer transfers—move at the speed of data, outcomes matter more than labels. When a financial institution is evaluating its vendors, it should ask if the fraud solution delivers proven real-world outcomes, or just fancy technical capabilities and hype. Here are some questions to ask:
Does it provide context and targeted insights for specific fraud scenarios, or just raw graph storage?
Does it unify messy data with proven entity resolution, or add yet another silo?
Does it increase relevant fraud alerts, or continue to deliver more false positives?
Looking ahead
Fraud leaders need proven, contextual insights into risk. Quantexa’s patented, proven Knowledge Graph (QKG), powered by its best-in-class entity resolution, provides the clarity, adaptability, and scale institutions need to fight fraud in an economy where speed and agility is everything.

 Loading...
Loading...