

You Can’t Automate Understanding, but You Can Automate Context
Why the real gap in enterprise AI isn't model intelligence but the context layer underneath it


In discussions about AI and enterprise decision‑making, it’s often said that human understanding cannot be automated. In an important sense, that’s true.
But while context is not the same as human understanding, automating context can advance it significantly. Especially at the point where data, decisions, and accountability meet.
That distinction becomes clearer when we place entity truths, knowledge graphs and their data foundations into the midst of the machine-human interface.
The semantics of “understanding”
In enterprise tech, “understanding” means at least three different things:
Human understanding (phenomenological)
Meaning, intent, judgement, consequence. The bit that involves stakes, responsibility, and lived context.Ontological understanding (organizational)
Complex enterprise (agentic/decisioning) systems interpret inputs, reason over representations based on agreed rules, and reliably produce good outputs. Yet inputs, rules and outputs change over time.Performative understanding (LLMs)
The system sounds coherent; it explains itself; it appears to “get it”. However, it can project overbearing and often false confidence. We need to understand how good its understanding is.
Many debates about AI “understanding” fail because they silently switch between the three. The overconfidence of the LLM – it thinks it knows, when it doesn’t – is a particular failing.
When someone says “you can’t automate understanding,” they’re usually gesturing at (1). But they’re increasingly navigating (3) with all its flaws, sometimes ‘guardrail-ing’ with a version of (2) which may or may not be architecturally sound or relevant for a given use case at a point in time.
The LLM sleight-of-hand: behaviour vs comprehension
LLMs are remarkable tools for automating language-shaped work, but they also create the risk that an illusion that articulates output implies comprehension, when it’s merely statistical probability.
An LLM can:
Draft a policy
Propose an architecture
Answer a customer
Generate code
Justify a decision…
…but that does not mean it has a stable internal model of:
What matters
What’s true
What is permitted
What changes what
Who is accountable
It just produces plausible statistically trained text, sometimes correct, sometimes catastrophically incorrect. It is exactly at that moment when the output looks confident that organizations get wrong-footed by the dreaded LLM-as-stochastic-parrot.
The issue isn’t the model so much as the context around it.
Knowledge graphs only drive context when embedding data in real-world entity relationships
Traditional enterprise AI has always had a blind spot: it’s great at scoring rows (and/ or columns), but struggles to reason across the relationships that connect them
A knowledge graph flips the table. It makes relationships first-class citizens: entities, connections, provenance, attributes, and (critically) the ability to trace why something is connected to something else. However, the knowledge graph only works when the entities are nailed down and contextualized as relevant to a situation – what at Quantexa we describe as a Contextual Fabric. An example: John Smith is registered in the database as aged 32, living in Boston, and owning 2 cars, like this:
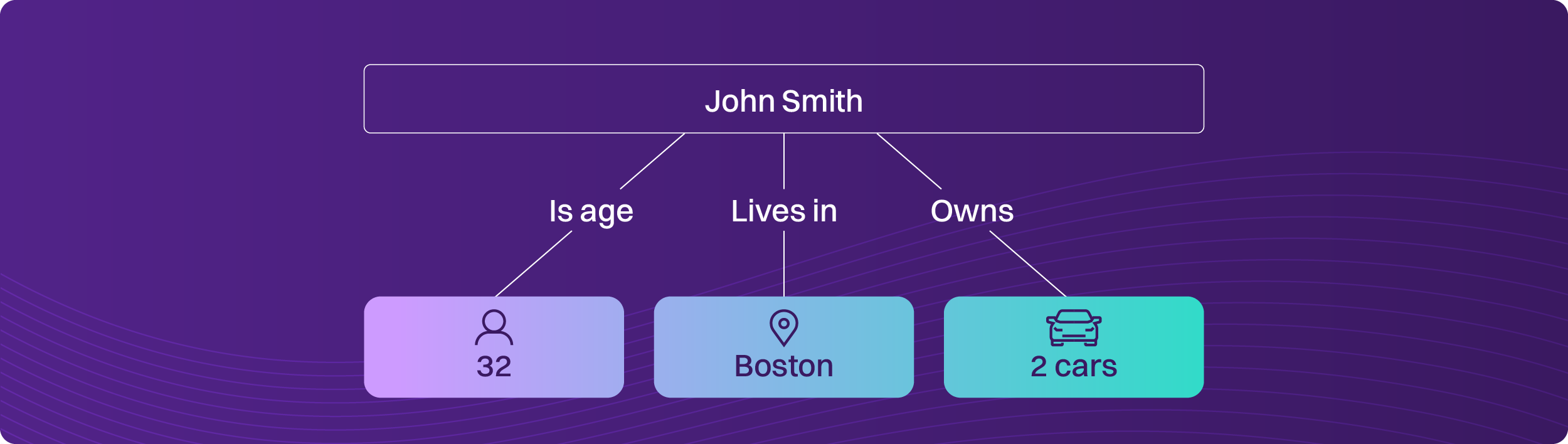
However, the database is wrong. It assumes, incorrectly, based on records combined from different data sources, there is one John Smith. However, there are actually two John Smiths. They each own one car, one being a resident of Boston MA and the other Boston, Lincolnshire. The database is a victim of “overlinking.” The graph is more accurately like this:
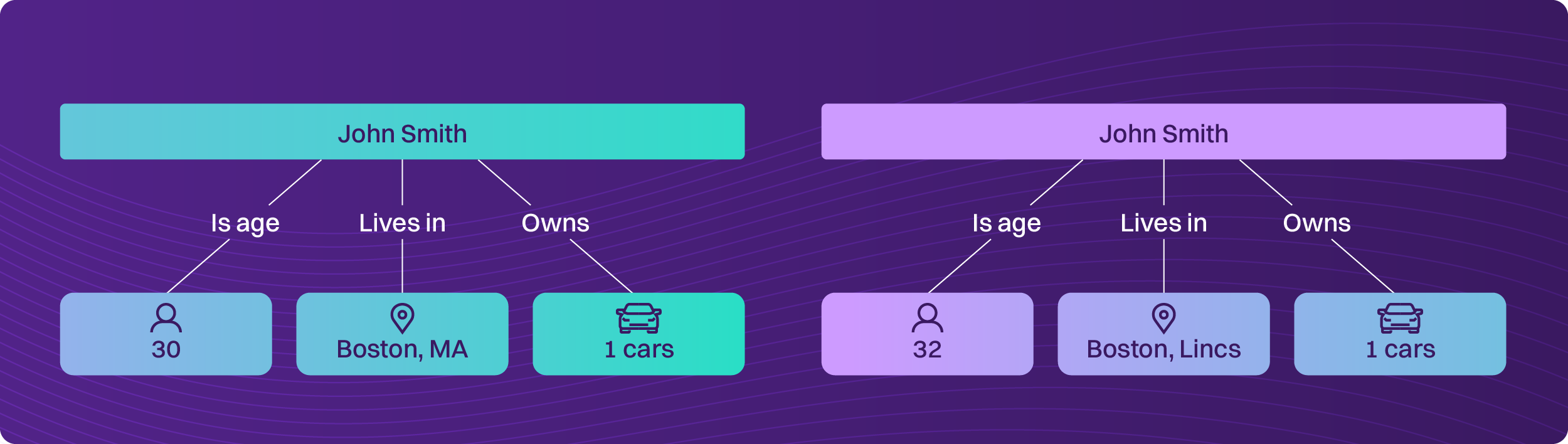
Then there’s the relevance of the rule or ontology:
John Smith (1) lives in Boston in Massachusetts in the USA and owns an expensive car
John Smith (2) lives in Boston in Lincolnshire in the UK and owns an expensive car
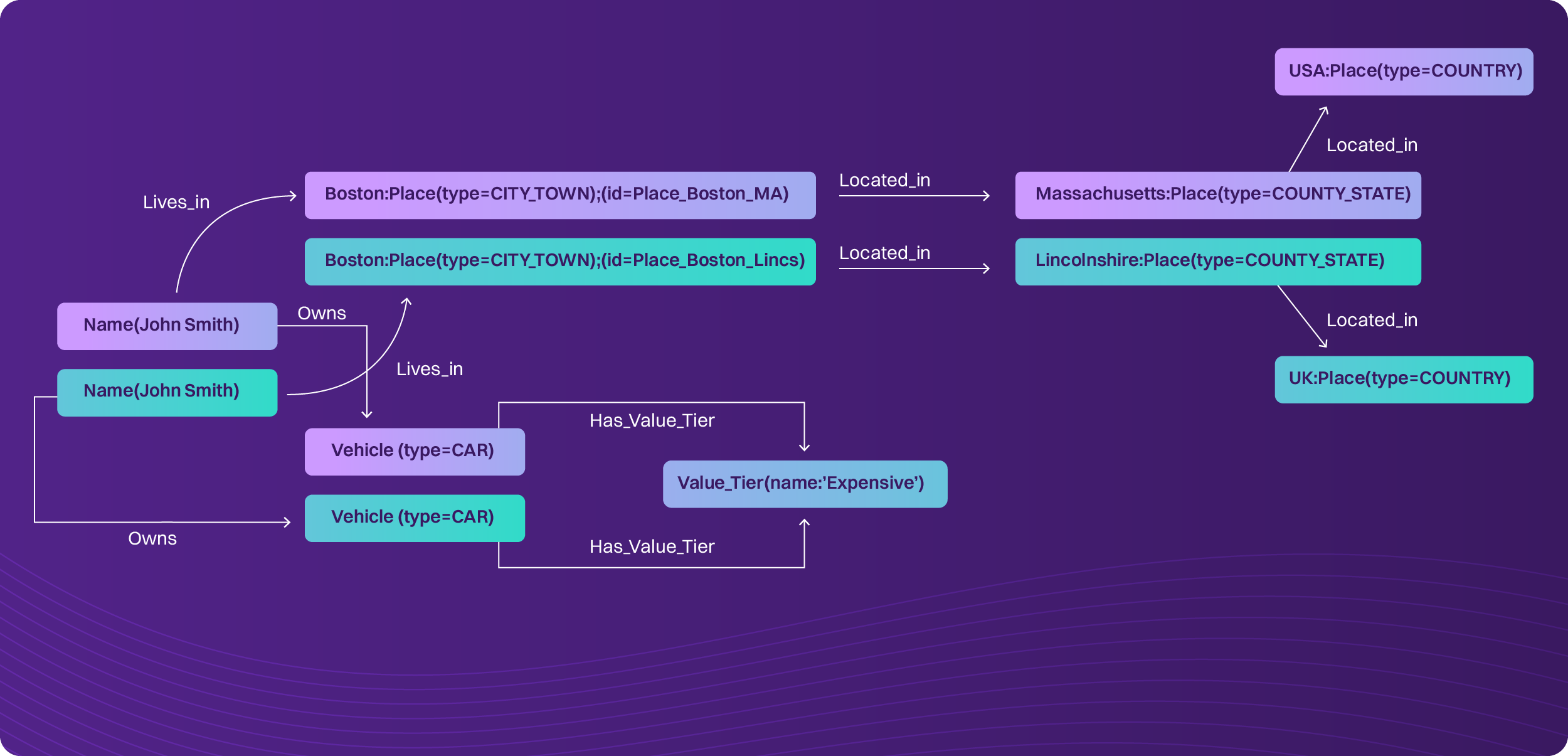
Fig 3: A simple ontology-style visualisation of the entities and relationships showing how the same “Boston” label resolves to different places via the hierarchy and therefore disambiguates John Smith (1) vs John Smith (2)).
We’re good, right? No, not when one John Smith drives an expensive car purchased though money laundering while the other John Smith drives an expensive car paid for from legitimate good business investments. Context, contingent on how the two John Smiths purchased the car, matters to the question asked: How is John Smith laundering money, or how can I approach John Smith to invest in my business? The latter can apply to both John Smiths, but you only want one of them to invest.
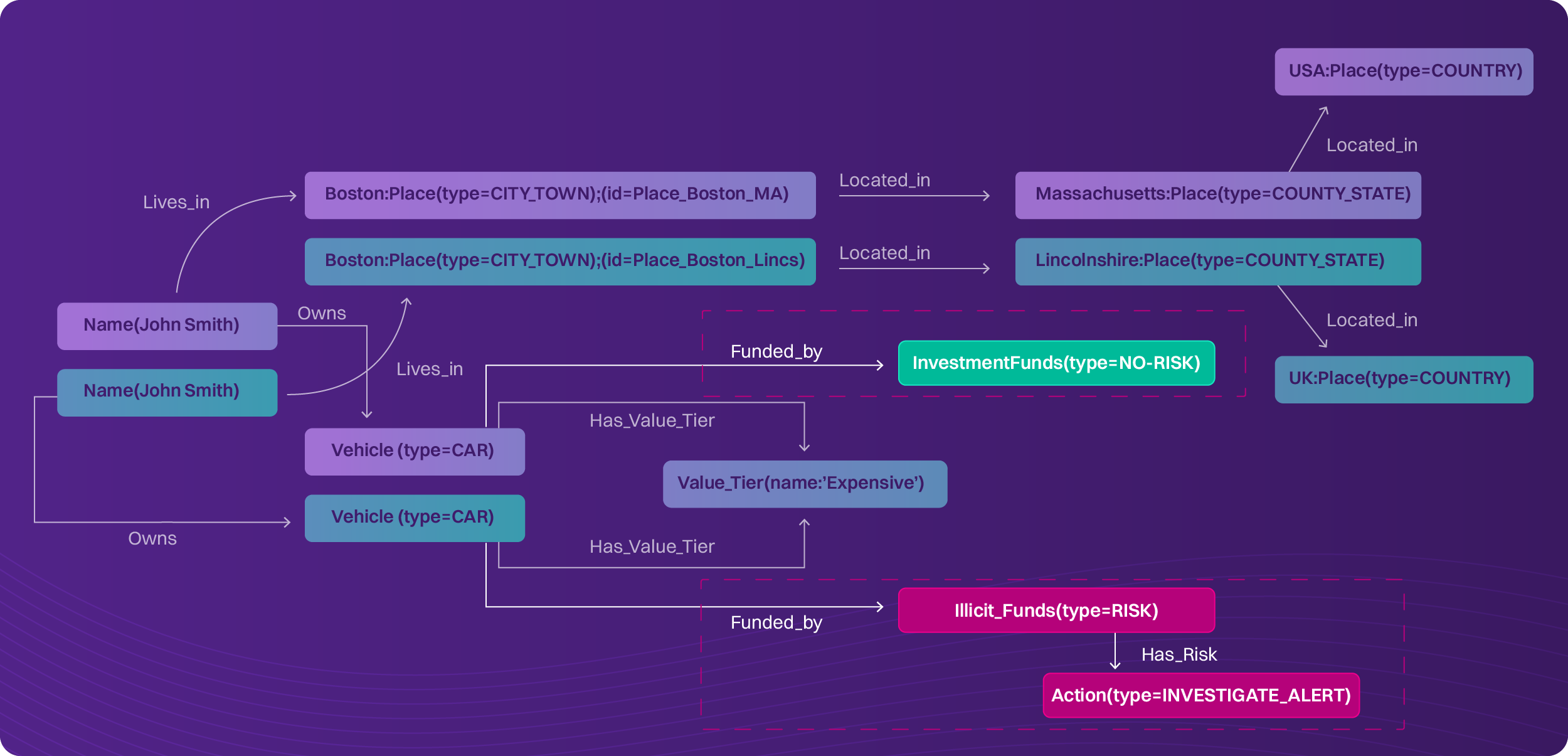 Fig 4: The real-world context of the two car purchases drives the entity knowledge and ontology/rules to act: to investigate one John Smith, or to seek investment from the good John Smith.
Fig 4: The real-world context of the two car purchases drives the entity knowledge and ontology/rules to act: to investigate one John Smith, or to seek investment from the good John Smith.
What matters is this: Knowledge graphs don’t make AI “understand”. When done well, they make contingent understanding available for decision-making across many use cases.
They create a substrate where:
Ambiguity is reduced (which “John Smith”?)
Entities are resolved (which records refer to the same real-world thing?)
Relationships are explicit (how did we get from A to B?)
Reasoning becomes inspectable (what path led to this conclusion?)
At Quantexa, our platform framing is very explicit on this. Unify data, resolve and understand entities, generate graphs, and use that contextual foundation for analytics, “trusted AI”, and decision workflows. This helps a) identify the network of suspected launderer John Smith for an investigation, and b) find credible paths and references to help prospect legitimate wealthy investor John Smith.
In the “you can’t automate understanding” debate, knowledge graphs centred on accurate entity knowledge sit in an awkward but powerful position: they don’t create human meaning, but when predicated on fact not fiction, they do give AI and humans a shared, structured context layer that makes many contingent decisions more reliable.
Context brings understanding within reach
A lot of what we call “understanding” in enterprises is often just people doing three jobs:
Disambiguation
“Are these two records the same entity?” E.g. “Is John Smith one or two distinct individuals?”Context assembly
“What else is connected that I should know about?” E.g. “How did John Smith pay for his car?”Justification
“Can I explain why this action is correct?” E.g. “Why did I ask John Smith to invest legitimately in my business?”
This is when graphs and entity knowledge, supported through impeccable entity resolution, change the economics.
Quantexa Entity Resolution is core to building “360-degree views” across siloed data, which then feeds graph generation, building and analyzing relationships at scale, and downstream decisioning through analytical and operational workflows.
When you industrialise disambiguation + context assembly + justification, you empower the human understanding required to do the job.
Not because the machine “understands”, but because the environment becomes more legible. It makes stochastic LLMs less wrong and less hallucinatory but also through relationship-orientation gives LLM retrieval a structure (entities + relations) that makes relationship-based questions more tractable and answers more explainable.
So… Quantexa helps “automate understanding”?
If by “understanding” you mean functional understanding, the operational ability to interpret messy reality and take reliable action, our platform is explicitly built to automate a big chunk of the prerequisite work directly from data through its “Contextual Fabric”. It can:
Unify and contextualise siloed data into a reusable foundation
Resolve entities at scale, turning ambiguous records into coherent, real-world views
Generate and analyse graphs so decisions can use the network of relationships (not just the row in front of you)
Ground AI in truthful patterns, positioning graphs as part of how modern AI is grounded and operationalised.
Make the platform “agent ready” by emphasising trusted, contextualised data and auditable outcomes
That’s not “automating understanding” in the human sense. It is automating the construction of context, the real-world scaffolding that makes explainable and trustworthy decisions in AI possible at scale.
The shift from “smart models” to “legible systems”
The enterprise AI stack is slowly (and painfully) relearning old lessons from software engineering, library and museum curation, biological taxonomy, parenting, and even buying a house.
In practice, reliability comes less from clever tricks and more from disciplined structure.
Knowledge graphs, when centered on entity certainty, bring structure to help fill the missing layer between “AI demo” and “AI deployment” and between analytics and decisions. They:
Encode relationships truthfully
Expose provenance
Support traceability
Let you ask why
Adapt in time
What enterprises really want from AI
Most enterprises don’t actually want AI to “understand.” They want AI to be useful, predictable, and auditable. “Understanding” is ‘romantic’ and human, but business understanding only transpires through governance, operational consistency and accurate operations. If you can produce consistent outcomes, show your working, and, perhaps, survive a regulator’s questions, you’ve solved the problem of the mundane middle.
The obsession with computed “intelligence” can distract from the harder work of building legible data foundations. By extension, “blaming" AI doesn't get you anywhere and doesn't provoke change. Blaming a human can make a fix. This is uncomfortable for owners everywhere.
And the final really uncomfortable bit: Organizations purport “you can’t automate understanding” but this is distinct from automating context. They confuse “we can’t” with “we didn’t build the substrate.” Once you resolve entities, connect relationships, and expose why-paths, huge parts of what analysts used to do as “understanding work” become workflow.
It doesn’t remove people from the equation. It changes where their judgement is applied: setting intent and policy on one end, and owning accountability when things go wrong.
But the hard middle, assembling the world into a coherent picture, is precisely what our platform, through its Contextual Fabric, is designed to industrialise.
Watch our CTO, Jamie Hutton, explain how context turns ambiguous data into explainable outcomes in this end-to-end demo.


